Transformer Models
Vision Transformer (ViT)
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
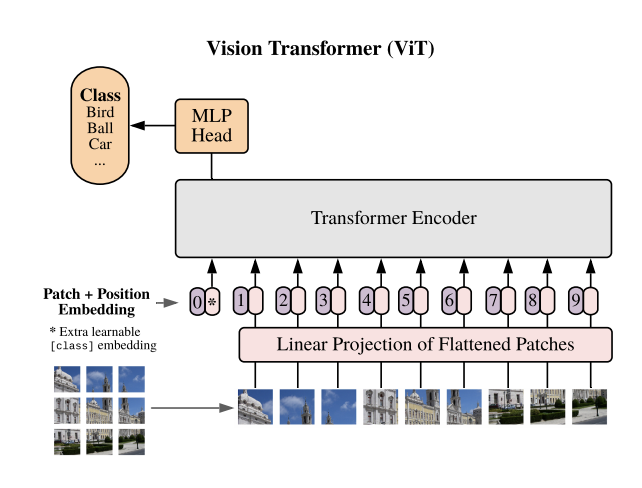
- Inductive biases in CNNs, which are lacking in ViTs:
- Translational Equivariance: an object can appear anywhere in the image, and CNNs can detect its features
- Locality: pixels in an image interact mainly with its surrounding pixels to form features
- ViTs are highly scalable and trained on massive amount of images, overcoming the need of these inductive biases
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
- In comparison to CNNs, ViT's weaker inductive bias is generally found to cause an increased reliance on model regularization or data augmentation ("AugReg") when training on smaller training datasets
- Scaling datasets with AugReg and compute
- Transfer is the better option
- More data yields more generic models
- Prefer augmentation to regularization
- How to select a model for further adaption for an end application? One way is to run downstream adaptation for all available pre-trained models and then select the best performing model, based on the validation score on the downstream task of interest. This could be quite expensive in practice
- Alternatively, one can select a single pre-trained model based on the upstream validation accuracy and then only use this model for adaptation, which is much cheaper
- Prefer increasing patch-size to shrinking the model size
Scaling Vision Transformers
- Scaling up compute, model and data together improves representation quality
- Representation quality can be bottlenecked by model size
- Large models benefit from additional data
| Name | Width | Depth | MLP | Heads | Mio. Param | GFLOPs (224²) | GFLOPs (384²) |
|---|---|---|---|---|---|---|---|
| s/28 | 256 | 6 | 1024 | 8 | 5.4 | 0.7 | 2.0 |
| s/16 | 256 | 6 | 1024 | 8 | 5.0 | 2.2 | 7.8 |
| S/32 | 384 | 12 | 1536 | 6 | 22 | 2.3 | 6.9 |
| Ti/16 | 192 | 12 | 768 | 3 | 5.5 | 2.5 | 9.5 |
| B/32 | 768 | 12 | 3072 | 12 | 87 | 8.7 | 26.0 |
| S/16 | 384 | 12 | 1536 | 6 | 22 | 9.2 | 31.2 |
| B/28 | 768 | 12 | 3072 | 12 | 87 | 11.3 | 30.5 |
| B/16 | 768 | 12 | 3072 | 12 | 86 | 35.1 | 111.3 |
| L/16 | 1024 | 24 | 4096 | 16 | 303 | 122.9 | 382.8 |
| g/14 | 1408 | 40 | 6144 | 16 | 1011 | 533.1 | 1596.4 |
| G/14 | 1664 | 48 | 8192 | 16 | 1843 | 965.3 | 2859.9 |
When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations
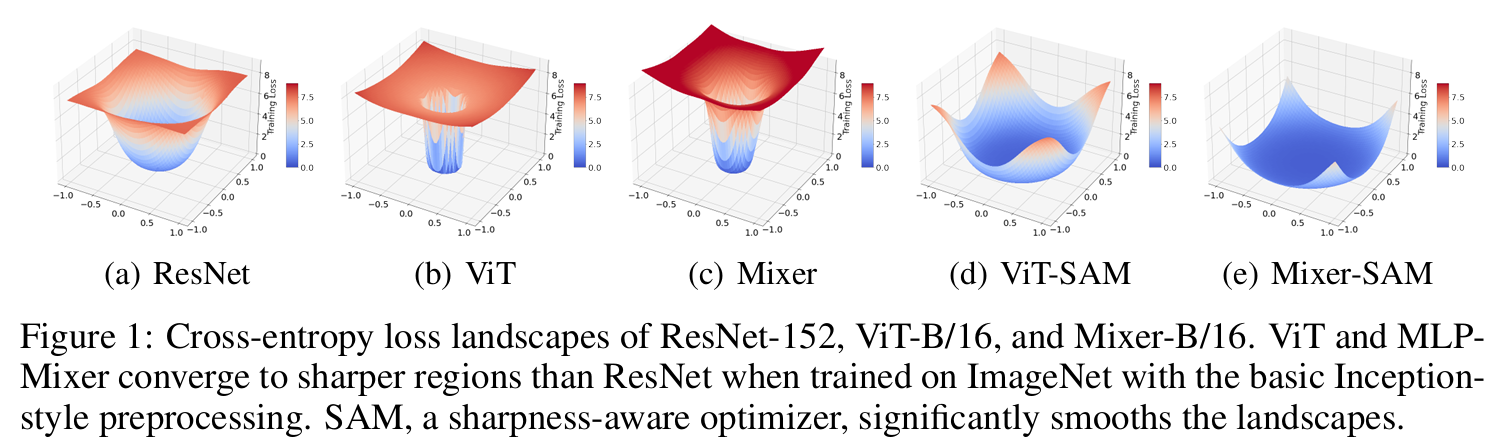
- ViTs can outperform ResNets of even bigger sizes in both accuracy and various forms of robustness by using a principled optimizer, without the need for large-scale pre-training or strong data augmentations
- Study from the lens of loss landscapes:
- Visualization and Hessian matrices of the loss landscapes reveal that Transformers and MLP-Mixers converge at extremely sharp local minima, whose largest principal curvatures are almost an order of magnitude bigger than ResNets'
- Such effect accumulates when the gradients backpropogate from the last layer to the first, and the intial embedding layer suffers the largest eigenvalue of the corresponding sub-diagonal Hessian
- The networks all have very small training errors, and MLP-Mixers are more prone to overfitting than ViTs of more parameters (because of the difference in self-attention)
- ViTs and MLP-Mixers have worse "trainabilities" than ResNets, following the neural tangent kernel analyses
- Sharpness-aware minimizer (SAM): explicitly smooths the loss geometry during model training
- The first-order optmizers (e.g. SGD, Adam) only seek the model parameters that minimize the training error, which dismiss the higher-order information such as flatness that correlates with generalization
- SAM strives to find a solution whose entire neighborhood has low losses rather than focus on any singleton point
- SAM incurs another round of forward and backward propagations to update , which will lead to around 2x computational cost per update
Training Vision Transformers with Only 2040 Images
- Self-supervised pretraining: parametric instance discrimination
- Supervised fine-tuning
TODO
Vision Transformer for Small-Size Datasets
Data Efficient Image Transformers (DeiT)
Training Data-Efficient Image Transformers & Distillation Through Attention
Hard Distillation
The student tries to recreate the labels predicted by the teacher:
- The first term is similar to soft distillation
- The second term is the distillation component, it is the cross-entropy loss between the softmax of students and labels of the teacher
- is the teacher's predicted label
Architecture
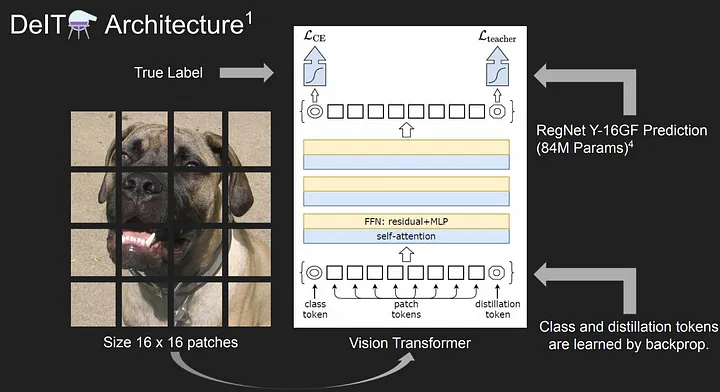
- Add an additional class-type token called distillation token: exactly like the CLS token, it's initialized randomly, is learnable, and has a fixed last position
- Uses hard distillation
- At inference time, the authors average the softmax of distillation and CLS token, then passed through softmax + argmax to get better results
- The teacher is RegNetY-16GF (84M parameters): using a convnet teacher gives better performance than using a transformer, probably due to the inductive bias inherited by the transformer through distillation
- Students outperformed teacher networks
The secret sauce: fine-tuning and augmentation:
- FixRes strategy: pretrain on , then fine-tune on
- Data augmentation: CutMix, MixUp, and RandAugment
DeiT III: Revenge of the ViT
Training Recipe
The proposed training recipe is based on ResNet Strikes Back and DeiT
3-Augment
RandAugment is widely employed for ViT while their policy was initially learned for convnets. Given that the architectural priors and biases are quite different in these architectures, the augmentation policy may not be adapted, and possibly overfitted considering the large amount of choices involved in their selection.

Inspired by self-supervised learning (SSL):
- Grayscale: favors color invariance and give more focus on shapes
- Solarization: adds strong noise on the color to be more robust to the variation of color intensity and so focus more on shape
- Gaussian Blur: in order to slightly alter details in the image
Simple Random Crop (SRC)

- Random Resized Crop (RRC) is commonly used, but it introduces some discrepancy between train and test images, as mentioned in FixRes
- RRC provides a lot of diversity and very different sizes for crops
- RRC is relatively aggressive in terms of cropping and in many cases the labelled object is not even present in the crop
- SRC covers a much larger fraction of the image overall and preserve the aspect ratio, but offers less diversity
Bidirectional Encoder representation from Image Transformers (BEiT)
BERT Pre-Training of Image Transformers
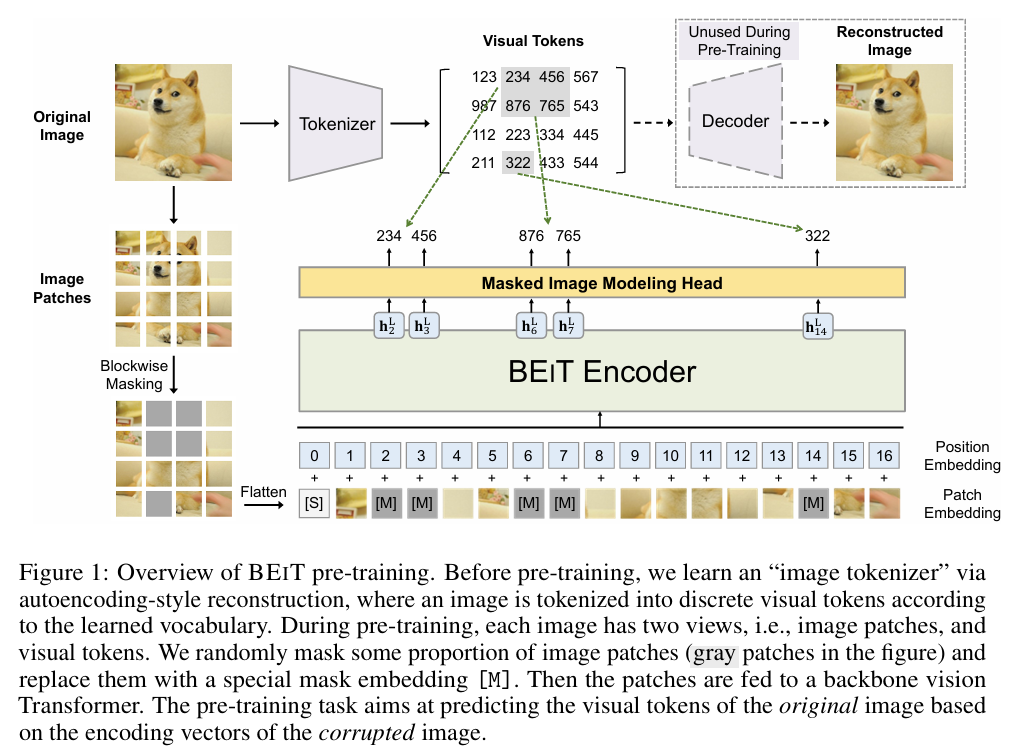
- A masked image modeling task to pretrain ViTs
Masked Autoencoders (MAE)
Masked Autoencoders Are Scalable Vision Learners
DINO
TODO
- Self-distillation with no labels
Emerging Properties in Self-Supervised Vision Transformers
MobileViT
MLP-Mixer
MLP-Mixer: An all-MLP Architecture for Vision
Swin Transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
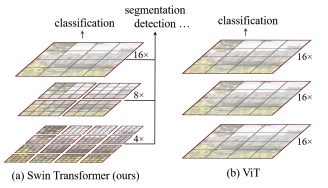
Shifted windows
- In the original ViT, attention is done between patch and all other patches, the processing time complexity increases quadratically with image dimensions
- Shifted window mechanism helps the model to extract features at variable scales and also restricts the computational complexity with respect to image size to linear
- Each window block is divided into patches and fed to model in same way the vision transformer processes the entire input image
- The self-attention block of the transformer computes the key-query weight for these patches within these windows
- This helps the model emphasize on small scale features, but since the relationship between the patches are computed within the windows self-attention mechanism, it's unable to capture the global context which is a key feature in transformers
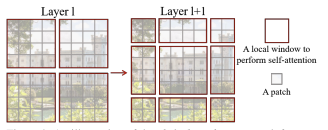
- Window partitioning in successive layers:
- In the first layer, the image is divided into windows by red boxes. Each window is further divided into patches denoted by gray boxes
- In the second layer, this window is shifted, and these windows are overlapping with the windows divided in the previous layer
Swin Transformer V2: Scaling Up Capacity and Resolution
Convolutional Vision Transformer (CvT)
Dilated Neighborhood Attention Transformer (DiNAT)
Conditioinal Position Encoding Vision Transformer (CPVT)
Transformer-iN-Transformer (TNT)
Tokens-to-Token ViT (T2T-ViT)
Pyramid Vision Transformer (PVT)
Class-Attention in Image Transformers (CaiT)
Going deeper with Image Transformers
Mobile-Former
Mobile-Former: Bridging MobileNet and Transformer
- Use MobileNet as a feature extractor, then fed into a transformer model
- Training MobileNet and ViT separately and then combining their predictions through ensemble techniques