CNN Models
ResNet
Deep Residual Learning for Image Recognition
Identity Mappings in Deep Residual Networks

The major differences between ResNetV1 and ResNetV2 are as follows:
- ResNetV1 adds the second non-linearity after the addition operation is performed between the and . ResNetV2 has removed the last non-linearity, thus clearing the path of the input to output in the form of identity connection.
- ResNetV2 applies Batch Normalization and ReLU activation to the input before the multiplication with the weight matrix (convolution operation). ResNetV1 performs the convolution followed by Batch Normalization and ReLU activation.
Resnet strikes back: An improved training procedure in timm
MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- Designed for mobile devices
- Depthwise Separable Convolutions: achieves high accuracy while minimizng computational overhead
- Channel-wise Linear Bottleneck Layers: help to further reduce the number of parameters and computational cost while maintaining high accuracy
Depthwise Separable Convolutions
- Depthwise Convolution + Pointwise Convolution
- Standard convolution
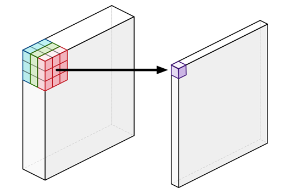
- Combines the values of all the input channels
- e.g. 3 channels --> 1 channel per pixel
- Depthwise convolution
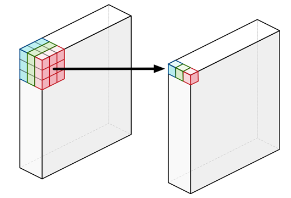
- Does not combine the input channels
- Convolves on each channel separately
- e.g. 3 channels --> 3 channels
- Pointwise convolution
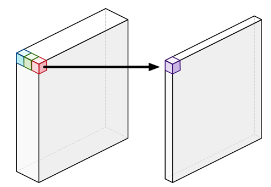
- Same as a standard convolution, except using a kernel
- Adds up the channels from depthwise convolution as a weighted sum
Channel-wise Linear Bottleneck Layers
3 main operations applied sequentially:
- Depthwise convolution: This step performs a convolution separately for each channel (a single color or feature) in the input image using a small filter (usually 3x3). The output of this step is the same size as the input but with fewer channels
- Batch normalization: This operation normalizes the activation values across each channel, helping to stabilize the training process and improve generalization performance
- Activation function: Typically, a ReLU (Rectified Linear Unit) activation function is used after batch normalization to introduce non-linearity in the network
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Searching for MobileNetV3
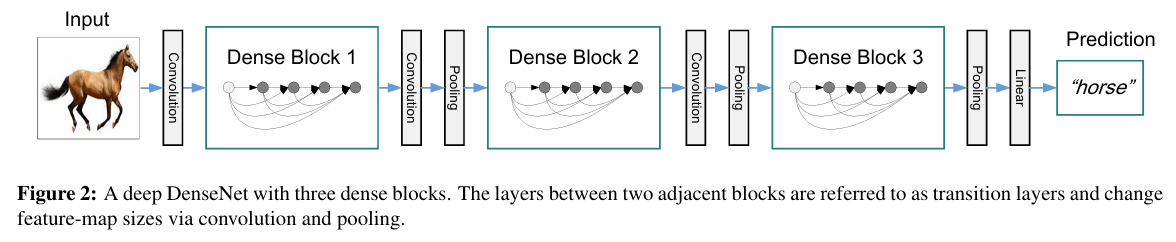
DenseNet
Densely Connected Convolutional Networks
Architecture
The key difference between ResNet and DenseNet is that in the latter case outputs are concatenated rather than added
As a result, we perform a mapping from to its values after applying an increasingly complex sequence of functions:
ShuffleNet
SENet
SqueezeNet
EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Conventional techniques of model scaling is arbitrary, it requires manual tuning and still often yields sub-optimal performance:
- Depth-wise
- Width-wise
- Scale up image resolution
Compound Model Scaling
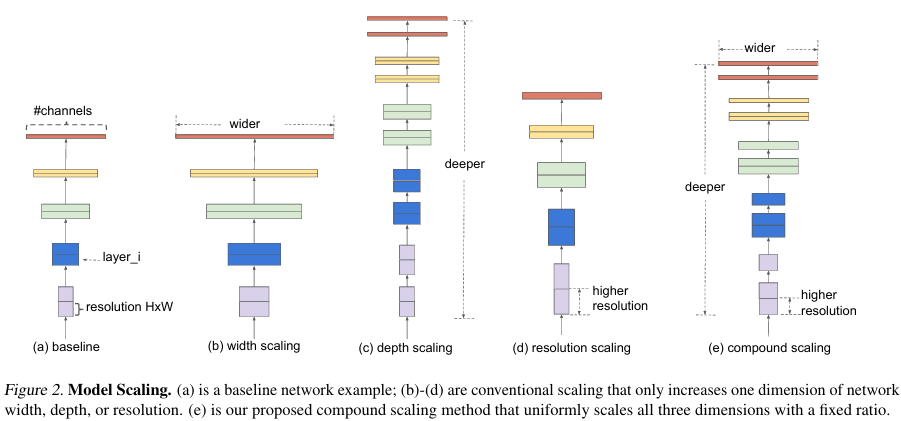
- Use a compound coefficient to uniformly scale network width, depth, and resolution
- The intuition for the network is, if the input image is bigger, them the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image
- FLOPS of a regular convolution operation is proportional to
- Scaling a ConvNet will approximately increase total FLOPS by
Architecture
EfficientNet-B0 is searched through neural architecture search, its architecture is similar to Mnas-Net
Starting from EfficientNet-B0, scale up:
- Fix , do grid search of
- Fix , scale up the baseline network with different
EfficientNetV2: Smaller Models and Faster Training
Bottlenecks of Efficient Net
- Training with very large image sizes is slow
- Smaller batch size is used, which drastically slows down the training
- FixRes can be used wherby using a smaller image size for training than for inference
- Depthwise convolutions are slow in early layers
- Fused-MBConv replaces the depthwise conv and expansion conv in MBConv with single regular conv
- When applied in early stage 1-3, Fused-MBConv can improve training speed wth a small overhead on parameters and FLOPs
- Equally scaling up every stage is sub-optimal
- EfficientNet equally scales up all stages using a simple compound scaling rule, yet the stages are not equally contributed to the training speed and parameter efficiency
- EfficientNetV2 use a non-uniform scaling strategy to gradually add more layers to later stages
- EfficientNet aggressively scale up image size, leading to large memory consumption and slow training
- In EfficientNetV2, the scaling rule is slightly modified and the maximum image size is restricted to a smaller value
Training-Aware NAS and Scaling
- The NAS search space is similar to PNASNet
- EfficientNetV2-S is scaled up to obtain EfficientNetV2-M/L using similar compound scaling as Efficient Net, with a few additional optimizations:
- The maximum inference image size is restricted to 480
- As a heuristic, more layers are added gradually to later stages
Progressive Learning

- Partially inspired by curriculum learing, which schedules training examples from easy to hard
- When image size is small, it has the best accuracy with weak augmentation; but for larger images, it performs better with stronger augmentation
- It starts with small image size and weak regularization, and then gradually increases the learning difficulty with larger image sizes and stronger regularization: larger Dropout rate, RandAugment magnitude, and mixup ratio
ResNeXt
Aggregated Residual Transformations for Deep Neural Networks
RegNet
NASNet
InceptionNet
ConvNeXt
A ConvNet for the 2020s
Introduction
- Without the ConvNet inductive biases, a vanilla ViT's global attention has a quadratic complexity with respect to the input size
- Hierachical Transformers, e.g. Swin Transformer's "sliding-window" strategy (e.g. attention within local windows) revealed that: The essence of convolution is not becoming irrelevant; rather, it remains much desired and has never faded
Training Techniques
Inspired by DeiT and Swin Transformers:
- Epochs: from 90 epochs to 300 epochs
- Optimizer: AdamW optimizer instead of Adam optimizer, which differs in how it handles weight decay
- Data augmentation: Mixup, Cutmix, RandAugment, Random Erasing
- Regularization: Stochastic Depth and Label Smoothing
This enhanced training recipe increased the performance of the ResNet50 model from 76.1% to 78.8%, implying that a significant portion of the performance difference between traditional ConvNets and vision Transformers may be due to the training techniques
Macro Design
Swin Transformers follow ConvNets and use a multi-stage design, where each stage has a different feature map resolution
- Changing stage compute ratio
- ResNet50 has 4 main stages with (3,4,6,3) blocks: a compute ratio of 3:4:6:3
- To follow Swin Transformer's compute ratio of 1:1:3:1, ConvNeXt adjusted the number of blocks on each stage of ResNet50 from (3,4,6,3) to (3,3,9,3)
- Changing the stage compute ratio improves the model accuracy from 78.8% to 79.4%
- Changing stem to "Patchify"
- The "stem" cell dictates how the input images will be processes at the network's beginning
- Due to the redundancy inherent in natural images, a common stem cell will aggresively downsample the input images to an appropriate feature map size in both standard ConvNets and ViTs
- At the start of ResNet, the input is fed to a stem of convolution layer with stride 2, followed by a max pool, used to downsample the image by a factor of 4
- Substiting the stem with a convolutional layer featuring a kernel size and a stride of 4 is more effective, effectively convolving them through non-overlapping patches
- Patchify serves the same purpose of downsampling the image by a factor of 4 while reducing the number of layers, it slightly improves the model accuracy from 79.4% to 79.5%
ResNeXt-ify
- ResNeXt demonstrates an improved trade-off between the number of floating-point (FLOPs) and accuracy compared to a standard ResNet
- The core component is grouped convolution, where the convolutional filters are separated into different groups
- ConvNeXt uses depthwise convolution, a special case of grouped convolution where the number of groups equals the number of channels
- Depthwise convolution is similar to the weighted sum operation in self-attention, which operates on a per-channel basis, i.e. only mixing information in the spatial dimension
- Depthwise convolution reduces the network FLOPs and the accuracy
- Following ResNeXt, ConvNeXt increases the network width from 64 to 96, the same number of channels as Swin-T
- This modification improves the model accuracy from 79.5% to 80.5%
Inverted Bottleneck

- An important aspect of the Transformer block is the inverted bottleneck, i.e. the hidden dimension of the MLP block is four times wider than the input dimension
- Despite the increased FLOPs for the depthwise convolution layer, the inverted bottleneck design reduces the whole ConvNeXt network FLOPs to 4.6G
- Slightly improves the performance from 80.5% to 80.6%
Larger Kernel Size

- ViT's non-local self-attention allows a broader receptive field of image features
- Swin Transformers' attention block window size is set to at least , surpassing the kernel size of ResNeXt
- Move up the depthwise convolution layer
- The repositioning enables the layers to efficiently handle computational tasks, while the depthwise convolution layer functions as a more non-local receptor
- By using a larger kernel size, ConvNeXt's performance increases from 79.9% () to 80.6 ()
Micro Design
- Activation: Replacing ReLU with GELU, and eliminating all GELU layers from the residual block except for one between two layers
- Normalization: Fewer normalization layers by removing two BatchNorm layers, and substituting BatchNorm with LayerNorm, leaving only one LayerNorm layer before the conv layers
- Downsampling Layer: Add a separate downsample layer in between ResNet stages
- These modifications improve the ConvNeXt accuracy from 80.6% to 82.0%
- The final ConvNeXt model exceeds Swin Transformer's accuracy of 81.3%
VAN
Visual Attention Network
Introduction
Applying self-attention in computer vision is challenging:
- Treating images as 1D sequences neglects their 2D structures
- The quadratic complecity is too expensive for high-resolution images
- It only captures spatial adaptability but ignores channel adaptability
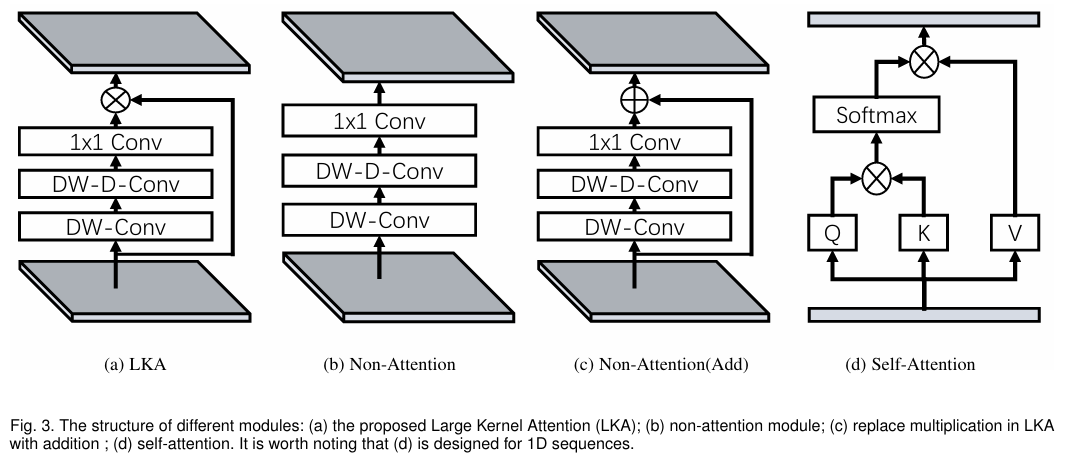
Large Kernel Attention (LKA)
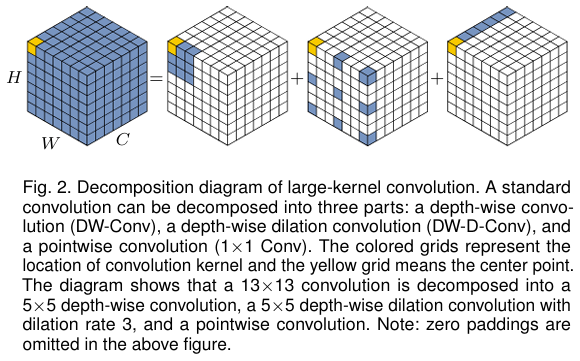
- Enable self-adaptive and long-range correlations in self-attention while avoiding its short-comings
- A large kernel convolution operation is decomposed to capture long-range relationship
- Specifically a convolution is decomposed into a depth-wise dilation convolution with dilation , a depth-wise convolution and a convolution
LKA Module:
- is the input feature
- denotes attention map
Visual Attention Network (VAN)
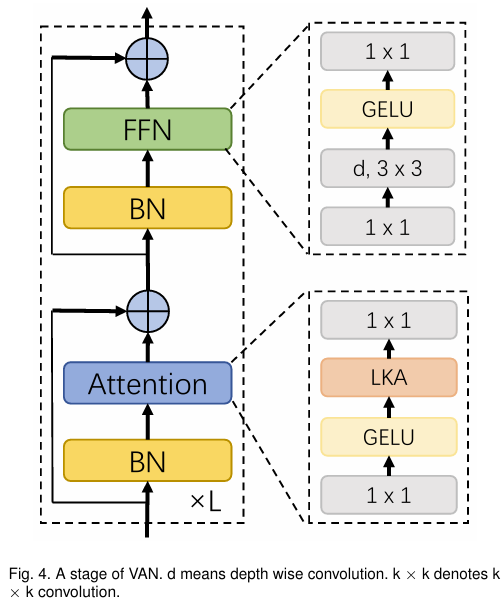
- Simple hierarchical strucure, i.e. a sequence of four stages with decreasing output spatial resolution
- With the decreasing of resolution, the number of output channels is increasing