Concepts
Empirical Risk Minimization
We are interested finding a function that minimized the expected risk:
with the optimal function:
- is the true risk if we have access to an infinite set of all possible data and labels
- In practical, the joint probability distribution is unknown and the only available information is contained in the training set
Thus, the true risk is replaced by the empirical risk, which is the average of sample losses over the training set :
with attempting to find a function in which minimizes the emprical risk:
- is a family of candidate functions
- In the case of CNNs, this involves choosing the relevant hyperparameters, model architecture, etc.
Thus finding a function that is as close as possible to can be broken down into:
- Choosing a class of models that is more likely to contain the optimal function
- Having a large and broad range of training examples in to better approximate an infinite set of all possible data and labels
Deep transfer learning
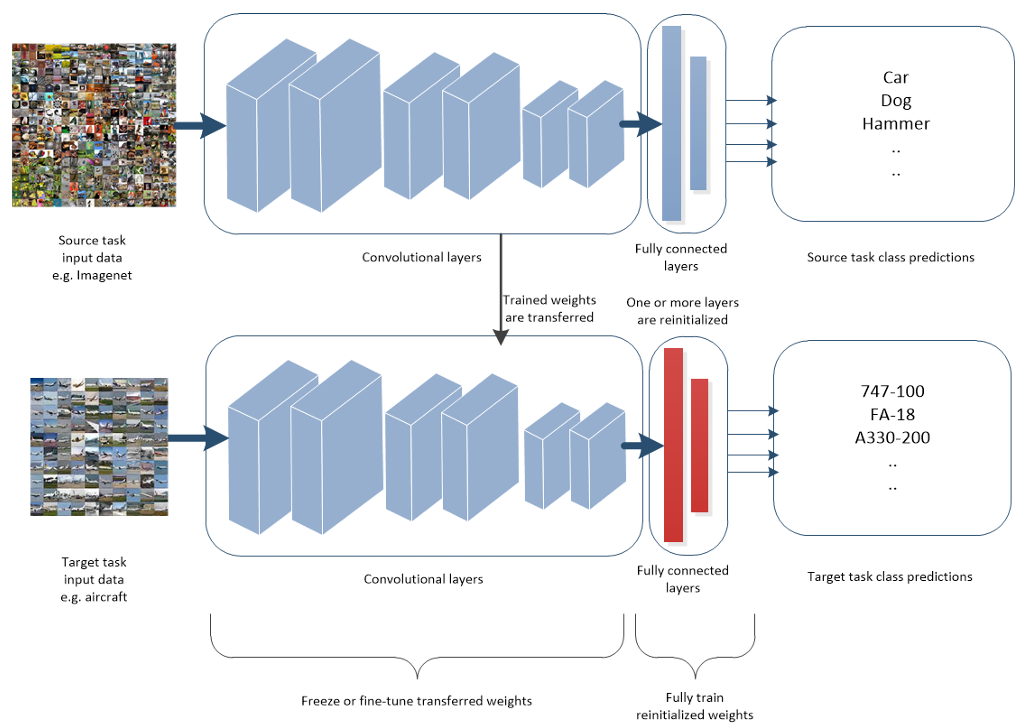
- Given a source domain and learning task , a target domain and learning task
- Deep transfer learning aims to improve the performance of the target model on the target task by initializing it with weights
- Weights are trained on source task using source dataset (pretraining)
- Where , or
- With deep neural networks, once the weights have been pretrained to respond to particular features in a large source dataset, the weights will not change far from their pretrained values during fine-tuning
Datasets commonly used in transfer learning for image classification
- Imagenet 1K, 5K, 9K, 21K: different subset of classes, e.g. 21K has 21000 classes
- JFT: internal Google Dataset
Negative Transfer
- If the source dataset is not well related to the target dataset, the target model can be negatively impacted by pretraining
- Negative transfer occurs when NTG is positive
- Divergence between the source and target domains, the size and quality of the source and target datasets affect negative transfer
Negative Transfer Gap (NTG)
- as the test error on the target domain
- as the specific transfer learning algorithm
- as the case where the source domain data/information are not used by the target domain learner
Class Activation Map (CAM)
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
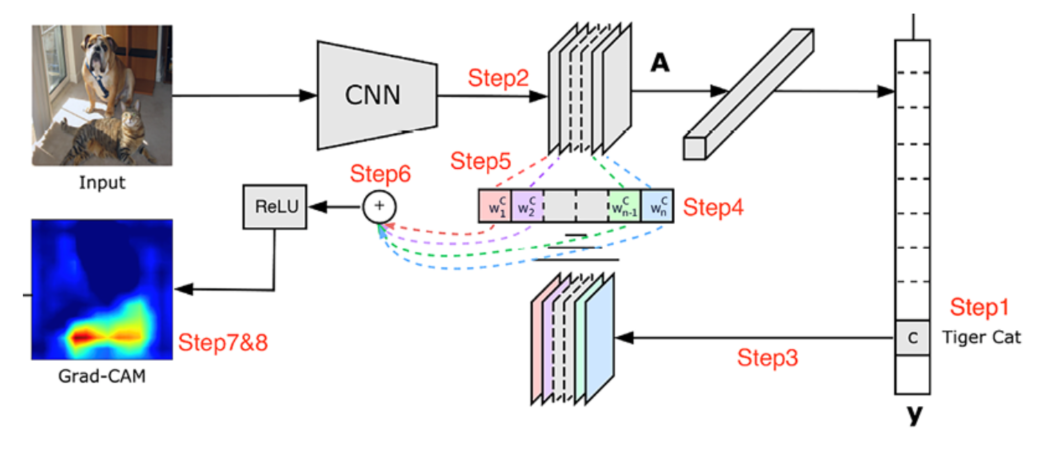
- If a certain pixel is important, then the CNN will have a large activation at those pixels
- If a certain convolutional channel is important with respect to the required class, the gradients at that channel will be very large
Caveats
- Imbalanced data
- Confusion matrix
- Loss function (binary or categorical cross-entropy) ensures that the loss values are high when the amount of misclassification is high
- Higher class weights to rare class image
- Over-sample rare class image
- Data augmentation
- Transfer learning
- The size of the object (small) within an image
- Object detection: divide input image into smaller grid cells, then identify whether a grid cell contains the object of interest
- Model is trained and inferred on images with high resolution
- Data drift
- The number of nodes in the flatten layer
- Typically around 500-5000 nodes
- Image size
- Images of objects might not lose information if resized
- Images of text might lose considerable information