Concepts
Refer to the LLM Bootcamp
Language Models (LMs)
- The models that assign a probability to each possible next word
- LMs can also assign a probability to an entire sequence
Representation vs Generative
- Representation Language Models
- Do not generate text but are commonly used for task-specific use cases
- e.g. Classification
- Generative Language Models
- LLMs that generate text
- e.g. GPT models
Causal / Autoregressive Language Models
- Iteratively predict words left-to-right from earlier words
- Conditional generation
Proprietary, Private Models
- Models that do not have their weights and architecture shared with the public
- Access through API, a paid service
- e.g. OpenAI's GPT-4 and Anthropic's Claude
Open Models
- Models that share their weights and architecture with the public to use
- Varying levels of licensing that may or may not allow commercial usage of the model
- e.g. Cohere's Command R, the Mistral models, Microsoft's Phi, Meta's Llama
- Leaderboard: https://huggingface.co/open-llm-leaderboard
Top-k Sampling
- Simple generalization of greedy decoding
- When , identical to greedy decoding
Steps:
- Choose in advance a number of words
- For each word in vocabulary , use the language model to compute the likelihood of this word given the context
- Sort the words by their likelihood, and throw away any word that is not one of the top most probable words
- Renormalize the scores of the words to be a legitimate probability distribution
- Randomly sample a word from within these remaining most-probable words according to its probability
Nucleus or Top-p Sampling
- To keep not the top words, but the top percent of the probability mass
- The hope is that the measure will be more robust in very different contexts, dynamically increasing and decreasing the pool of word candidates
Given a distribution , the top- vocabulary is the smallest set of words such that:
Temperature Sampling
- Don't truncate the distribution, but instead reshape it
- The intuition comes from thermodynamics:
- A system at a high temperature is very flexible and can explore many possible states
- A system at a lower temperature is likely to explore a subset of lower energy (better) states
- In low-temperature sampling, we smoothly increase the probability of the most probable words and decrease the probability of the rare words
- The lower is, the larger the scores being passed to the softmax
- Softmax tends to push high values toward 1 and low values toward 0
- Divide the logit by a temperature parameter
- Low-temperature sampling: , making the distribution more greedy
- High-temperature sampling: , flatten the distribution
Pretraining
Self-supervised Training Algorithm
- Cross-entropy loss: the negative log probability the model assigns to the next word in the training sequence
- Teacher forcing: always give the model the corrext history sequence to predict the next word
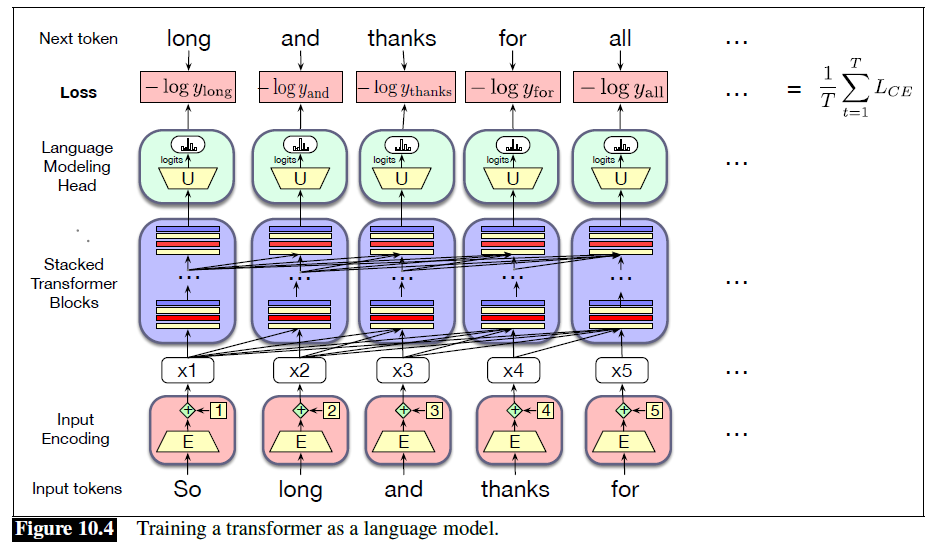
- At each step, given all the preceding words, the final transformer layer produces an output distribution over the entire vocabulary
- During trianing, the probabiliy assigned to the correct word is used to calculate the cross-entropy loss for each item in the sequence
- The loss for a training sequence is the average cross-entropy loss over the entire sequence
Training Corpora
- Mainly trained on text scraped from the web, augmented by more carefully curated data
- e.g. Common Crawl, The Pile
- Likely to contain many natural examples
- e.g. question-answer pairs (e.g. from FAQ lists), translations of sentences between various languages, documents together with their summaries
Filtering for quality and safety
- Pretraining data drawn from the web is filtered for both quality and safety
- Quality filtering:
- Subjective, different quality filters are trained in different ways, but often to value high-quality reference corpora like Wikipedia, books, and particular websites
- To avoid websites with lots of PII (Personal Identifiable Information) or adult content
- Removes boilerplate text
- Deduplication, various levels: remove duplicate documents, duplicate web pages, or duplicate text
- Safety filtering:
- Subjective
- Often includes toxicity detection
Evaluation
Perplexity
- Because perplexity depends on the length of a text, it is very sensitive to differences in the tokenization algorithm
- Hard to exactly compare perplexities produced by two language models if they have very different tokenizers
- Perplexity is best used when comparing language models that use the same tokenizer
Other factors
- Task-specific metrics that allow us to evaluate how accuracy or correct language models are at the downstream tasks
- How big a model is, and how long it takes to train or do inference
- Constraints on memory, since the GPUs have fixed memory sizes
- Measuring performance normalized to a giving compute or memory budget, or directly measure the energy usage of the model in kWh or in kilograms of emitted
- Fairness: because language models are biased
- Leaderboard: e.g. Dynabench, HELM
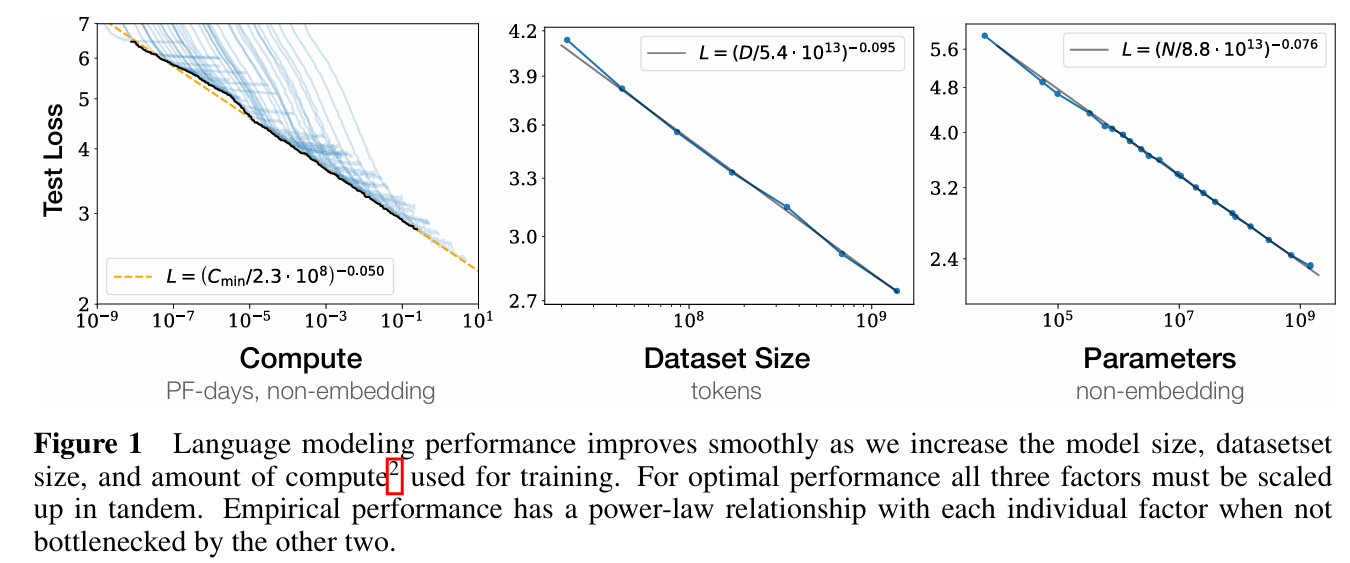
Scale
The performance of LLMs are mainly determined by 3 factors:
- Model Size:
- The number of parameters not counting embeddings
- Improve a model by adding parameters (adding more layers or having wider contexts or both)
- Dataset Size:
- The amount of training data
- Improve a model by adding more training data
- Amount of Compute Used for Training:
- Improve a model bt training for more iterations
Scaling Laws
- Loss as a function ofthe number of non-embedding parameters , the dataset size , and the compute budget :
- The constants depend on the exact transformer architecture, tokenization, and vocabulary size, so rather than all the precise values, scaling laws focus on the relationship with loss
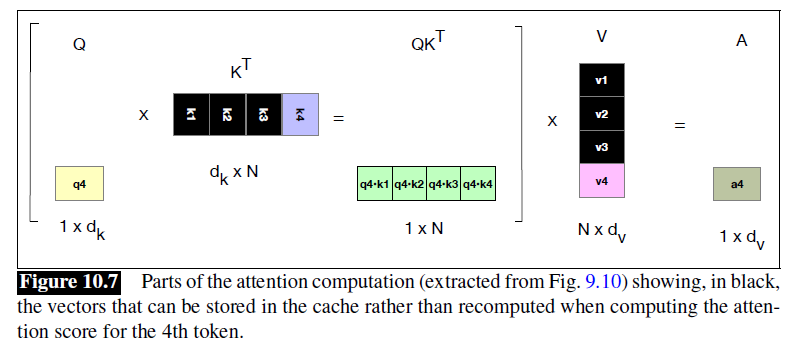
KV Cache
- The attention vector can be very efficiently computed in parallel for training
- Not the case during inference, because we iteratively generate the next tokens one at a time. For a new token just generated, call it , we need to compute its query, key, values by multiplying by , , , respectively
- But a waste of computation time to recompute the key and value vectors for all the prior tokens
- Instead of recomputing, whenever we compute the key and value vectors we store them in memory in the KV cache, and then we can just grab them from the cache when we need them
Inference
- Inference is divided into two phases: prefilling and decoding
- Apart from the model size, the model architecture also impacts latency
- The impacts of model architecture on inference speed is more significant at prefill stage than decode stage
- The computational density in the prefill stage is higher, making it more likely to be compute-bound, while the decode stage is primarily memory-bound
- e.g. Wider and shallower models have higher computational parallelism
- Due to
llama.cppdefaulting to allocate KV cache and compute buffer according to the maximum context length of the model, models that support longer contexts end up consuming significantly more memory than others - Runtime memory usage is generally linearly correlated with the model’s parameter count. A few models have larger memory usage compared to others with similar parameter counts, typically due to their larger vocabulary sizes.
Prefill
- Often regarded as the dominate phase in end-to-end LLM inference on devices, since on-device LLLM tasks often involve long-context understanding for context-awareness or personalization need
- The input prompt is processed to generate a KV Cache
- Where multiple tokens in the prompt can be computed in parallel
- First token latency: the time it takes to process all tokens in the prompt
- Higher degree of parallelism, thus more suitable for GPUs which have more parallel computing units
- e.g. On the Meizu 18 pro, the latency rises sharply from 1 to 10 tokens and then levels off after 10 tokens. This initial steep rise in latency from 1 to 10 tokens is due to the temperature increase, which triggers the Dynamic voltage and frequency scaling (DVFS) or thermal throttling to adjust power consumption and frequency, thereby reducing computational efficiency
Decode
- Also known as the autoregressive phase
- Generates one token at a time, incorporating it into the KV Cache
- Simultaneously, this token is used in predicting the next token
- Decode latency per token