Object Detection
Workflow (Few-shot)
- Creating ground-truth data that contains labels of the bounding box and class corresponding to various objects present in the image
- Coming up with mechanisms that scan through the image to identify regions (region proposals) that are likely to contain objects
- Creating the target class variable by using the IoU metric
- Creating the target bounding-box offset variable to make corrections to the location of the region proposal in step 2
- Building a model that can predict the class of object along with the target bounding-box offset corresponding to the region proposal
- Measuring the accuracy of object detection using mean average precision (mAP)
Models
R-CNN: Regions with CNN features
Rich feature hierarchies for accurate object detection and semantic segmentation
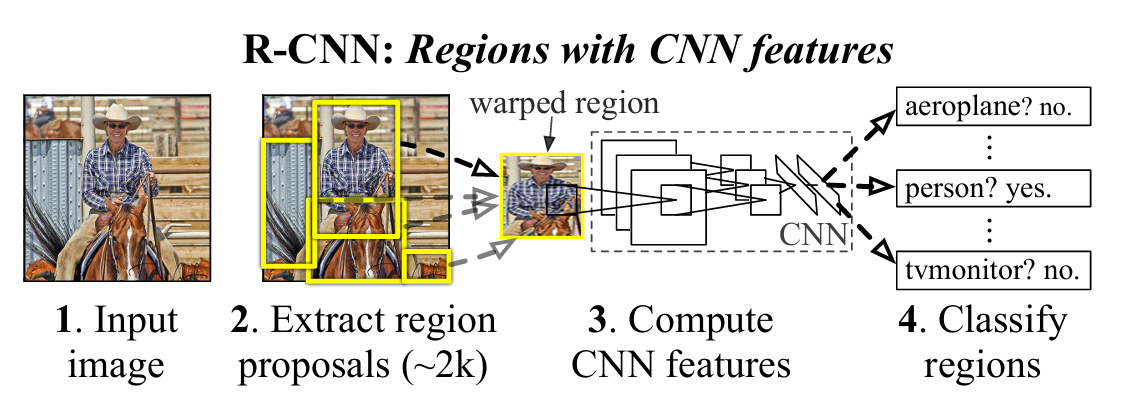
Workflow:
- Extract region proposals with selective search from an image. We need to ensure that we extract a high number of proposals to not miss out on any potential object within the image.
- Resize (warp) all the extracted regions to get regions of the same size.
- Pass the resized region proposals through a network. Typically, we pass the resized region proposals through a pretrained model, such as VGG16 or ResNet50, and extract the features in a fully connected layer.
- Create data for model training, where the input is features extracted by passing the region proposals through a pretrained model. The outputs are the class corresponding to each region proposal and the offset of the region proposal from the ground truth corresponding to the image.
- If a region proposal has an IoU greater than a specific threshold with the object, we create training data.
- We calculate the offset between the region proposal bounding box and the ground-truth bounding box as the differencebetween the center coordinates of the two bounding boxes
(dx, dy), and the difference between the height and width of the bounding boxes(dw, dh)
- Connect two output heads, one corresponding to the class of image and the other corresponding to the offset of region proposal with the ground-truth bounding box, to extract the fine bounding box on the object
- Train the model after writing a custom loss function that minimizes both the object classification error and the bounding-box offset error
Caveats:
- The feature vector generated by the CNN, is consumed by a binary SVM trained for each class independently
Fast R-CNN
Fast R-CNN
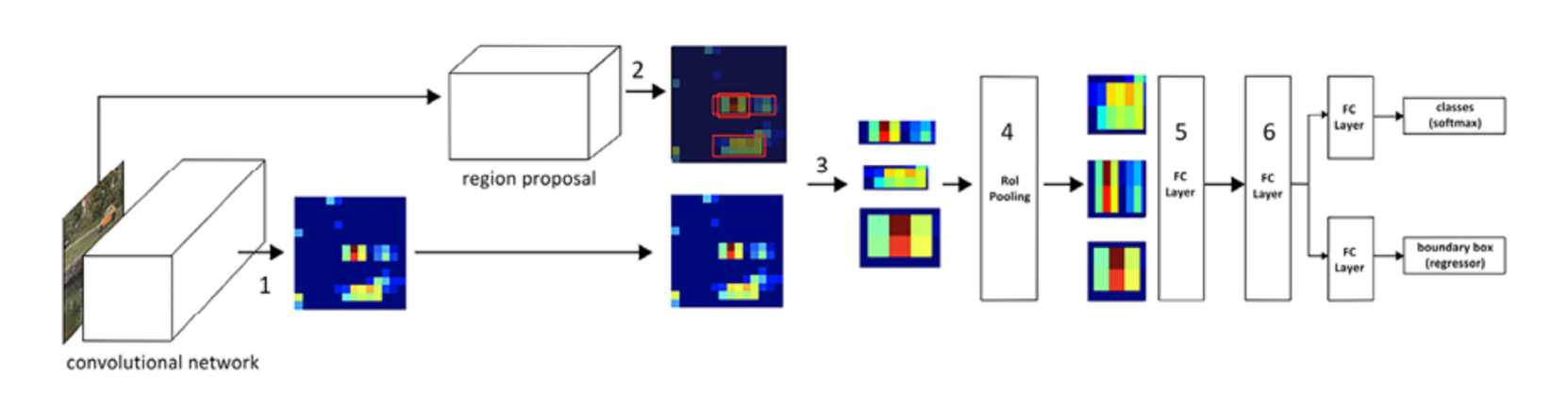
Advantages of Fast-RCNN over RCNN
- Fast-RCNN passes the entire image through the pretrained model to extract the features, and then fetches the region of features that corresponds to the region proposals (obtained from selective search) of the original image
- R-CNN generates region proposals for each image, resizing the crops of regions, and extracting features corresponding to each crop (region proposal) create a bottleneck
Workflow:
- Pass the image through a pretrained model to extract features prior to the flatenning layer
- Extract region proposals corresponding to the image
- Extract the feature map area corresponding to the region proposals
- Pass the feature maps corresponding to region proposals through the region of interest (RoI) pooling layer one at a time
- thus all feature maps of region proposals have a similar shape
- Pass the RoI pooling output value through a fully connected layer
- Train the model to predict class and offsets corresponding to each region proposal
Faster R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
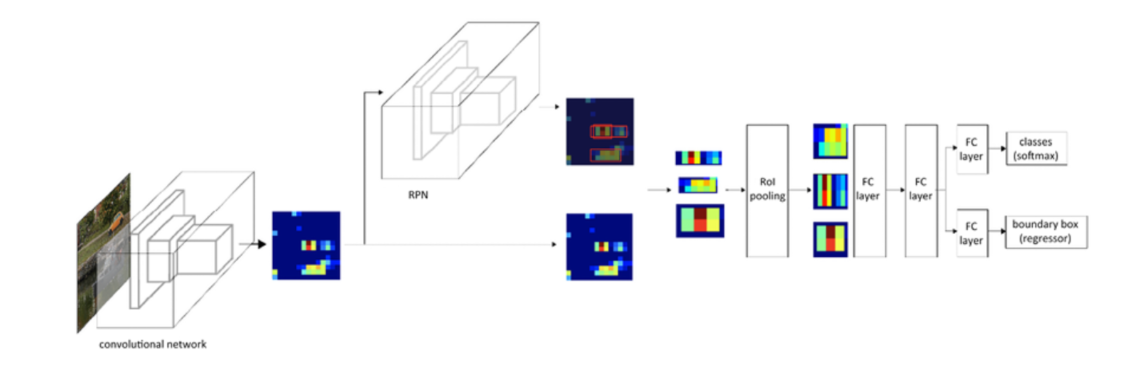
Advantages of Faster R-CNN over Fast R-CNN
- Replace selective search with RPN: reduce region proposals without loss of accuracy
- Fast-RCNN: selective search usually generates a lot of region proposals
- End-to-end training: RPN is jointly trained with the rest of the model
- RPN learns to generate high-quality region proposals
- the objective function of the faster R-CNN includes not only the class and bounding box prediction in object detection, but also the binary class and bounding box prediction of anchor boxes in the region proposal network
RPN Workflow:
- Use a convolutional layer with padding of 1 to transform the CNN output to a new output with channels
- Each unit along the spatial dimensions of the CNN-extracted feature maps gets a new feature vector of length
- Centered on each pixel of the feature maps, generate multiple anchor boxes of different scaled and aspect ratios and label them
- Using the length- feature vector at the center of each anchor box, predict the binary class (background or objects) and bounding box for this anchor box
- Consider those predicted bounding boxes whose predicted classes are objects. Remove overlapped results using non-maximum suppression. The remaining predicted bounding boxes for objects are the region proposals required by the region of interest pooling layer
YOLO
You Only Look Once: Unified, Real-Time Object Detection
Advantages of YOLO over Faster-RCNN
- One-stage vs Two-stage Detectors
- Faster R-CNN: RPN (proposed regions are sparse as the potential bounding box candidates can be infinite) + Classifier (predicts class and bounding box)
- YOLO: runs detection directly over a dense sampling of possible locations
- YOLO looks at the whole image while predicting the bounding box corresponding to an image
- Faster R-CNN: in the fully connected layer, only the detected region's RoI pooling output is passed as input
- in case of regions that do not fully encompass the object, the network has to guess the real boundaries of the object, as it has not seen the full image (but has seen only the region proposals)_
SSD
https://lilianweng.github.io/posts/2018-12-27-object-recognition-part-4/
- TO-DO
DETR
Concepts
Felzenszwalb's algorithm
Efficient Graph-Based Image Segmentation
- segmentation based on the color, texture, size, and shape compatibility of content within an image
Selective Search
Selective Search for Object Recognition
- region proposal algorithm
- generate proposals of regions that are likely to be grouped together based on their pixel intensities
- group pixels based on the hierarchical grouping of similar pixels (leverages the color, texture, size, and shape compatibility of content within an image)
- Workflow:
- over-segments an image by grouping pixels based on the preceding attributes
- iterates through these over-segmented groups and groups them based on similarity
- at each iteration, it combines smaller regions to form a larger region
Non-max suppression
- non-max: boxes that don't have the highest probability of containing an object
- suppresion: discarding those boxes
- Workflow:
- identify the bounding box that has the highest probability of containing the object
- discard all the other bounding boxes that have an IoU below a certain threshold with the box (highest probability containing an object)
Mean average precision
- Precision:
- True positive: bounding boxes that predicted the correct class of object and have an IoU with a ground truth that is greater than a certain threshold
- False positive: bounding boxes that predicted the class incorrectly or have an overlap that is less than the defined threshold with the ground truth
- If there are multiple bounding boxes that are identified for the same ground-truth bounding box, only one box can be a true positive, and everything else is a false positive
- Average precision: average of precision values calculated at various IoU thresholds
- mAP: average of precision values calculated at various IoU threshold values across all the classes of objects
RoI Pooling
- ensures fixed-size output for varying RoI dimensions
Anchor boxes
- handy replacement for selective search
- majority of objects have a similar shape, e.g. the bounding box for a person will have a greater height than width
- objects of interest might be scaled, but maintains the aspect ratio (height/width)
- define the anchor boxes with heights and width representing the majority of object's bounding boxes within the dataset
- obtained by using K-means clustering on top of the ground-truth bounding boxes
- also create anchor boxes with varying scales (same center but different aspect ratios)
- Workflow:
- slide each anchor box over an image from top left to bottom right
- the anchor box with a high IoU with the object will have a label that mentions it contains an objects, otherwise will be labelled as
0
Region proposal network (RPN)
- RPN vs selective search:
- selective search gives us a region candidate based on a set of computations on top of pixel values (done outside the neural network)
- RPN generates region candidates based on anchor boxes and the strides with which anchor boxes are slid over the image
- Workflow:
- Slide anchor boxes of different aspect ratios and sizes across the image to fetch crops of an image
- Calculate the IoU between the ground-truth bounding boxes of objects in the image and the crops obtained in the previous step
- Preparing the training dataset in such a way that crops with an IoU greater than a threshold contain an object, and crops with an IoU less than a threshold do not contain an object
- Train the model to identify regions that contain an object
- Perform NMS to identify the region candidate that has the highest probability of contaning an object and eliminate other region candidates that have a high overlap with it